Additional content for Data structures based on k-mers for querying large collections of sequencing datasets
July, 23th 2020.
Hi all,
In a summer series of blog posts, I will follow up on some data-structures that have been mentioned in our manuscript Data structures based on k-mers for querying large collections of sequencing datasets[1], but that would benefit from more insight. Today I focus on Othello hashing and its application to bioinformatics.
As a short reminder, our manuscript deals with structures indexing sets of read sets for querying sequence presence/absence. Let’s assume you have the genomic signature of a mutation, that you’d like to look for in a collection of samples (read datasets). These data-structures allow you to
- 1-index the whole collection of datasets (up to a few thousand for eukaryotes),
- 2-query your sequence and know whether it is present/absence in each dataset.
The data volume to handle is tremendous. One of the main tricks used by the surveyed methods is to represent the samples as sets of k-mers (i.e., fixed-length words extracted from the reads, typically 21-31 bases-sized) instead of multi sets of reads (queries are also performed using the k-mers of the sequence). So a compulsory stage is to index all these k-mers.
Today I’ll focus on the data-structures used to index k-mer sets (and I’ll restrain to those that are indeed used in the surveyed methods). Some of them are very atomic, what I mean is that they can be used as-is to index k-mers; others are like Russian dolls, these data-structures integrate other, often more low-level data-structures. For people who are already familiar with Bloom filters, the interesting part starts at the Othello section.
Indexing sets of k-mers
One of the simplest, most famous one is the Bloom filter. It has been so helpful and well-described in bioinformatics that I don’t feel the need to introduce it again. You can find plenty of good descriptions of the Bloom filter online, here is just an example: llimllib.github.io/bloomfilter-tutorial/. They basically tell you if an element is present or not in a set, with false positives (no false negatives).
In methods such as the different Sequence Bloom Trees [2], [3], [4], [5] and BIGSI and its refinement [6], [7], there is a one-to-one correspondence between Bloom filters and datasets. Each dataset is represented by a single Bloom filter, even if it means that k-mers can be redundant across datasets.
Bloom filters pertain to the large family of hash-based techniques, that rely on hash functions. Hash functions are functions used to map elements (of arbitrary length, such as a sequence) to fixed-sized numeric values. For instance, for the sequence “BIOINFO”, a (dummy) hash function gets the ASCII representation of the last character and applies a modulo (10). Working with the decimal values, we obtain 79 for O, and 79%10=9 as a final value.
Another data-structure based on hash functions is the quotient filter (and the counting quotient filter). Again for these methods, there already exist online documentation such as: gakhov.com/articles/quotient-filters.html , blog.acolyer.org/2017/08/08/a-general-purpose-counting-filter-making-every-bit-count/.
They are somehow related to the Bloom filter, but can in certain cases guarantee no false positives. Counting quotient filters are used in Mantis [8].
Othello hashing in bioinformatics
Intuition of Othello hashing
A third method that I believe is less popularized is Othello hashing. It was introduced by Yu et al.[9], it is a hashing technique that realizes a slightly different goal than Bloom filters and quotient filters. The original article is motivated by network algorithms and quite far from bioinformatics. Here I’ll give you an intuition of how it works.
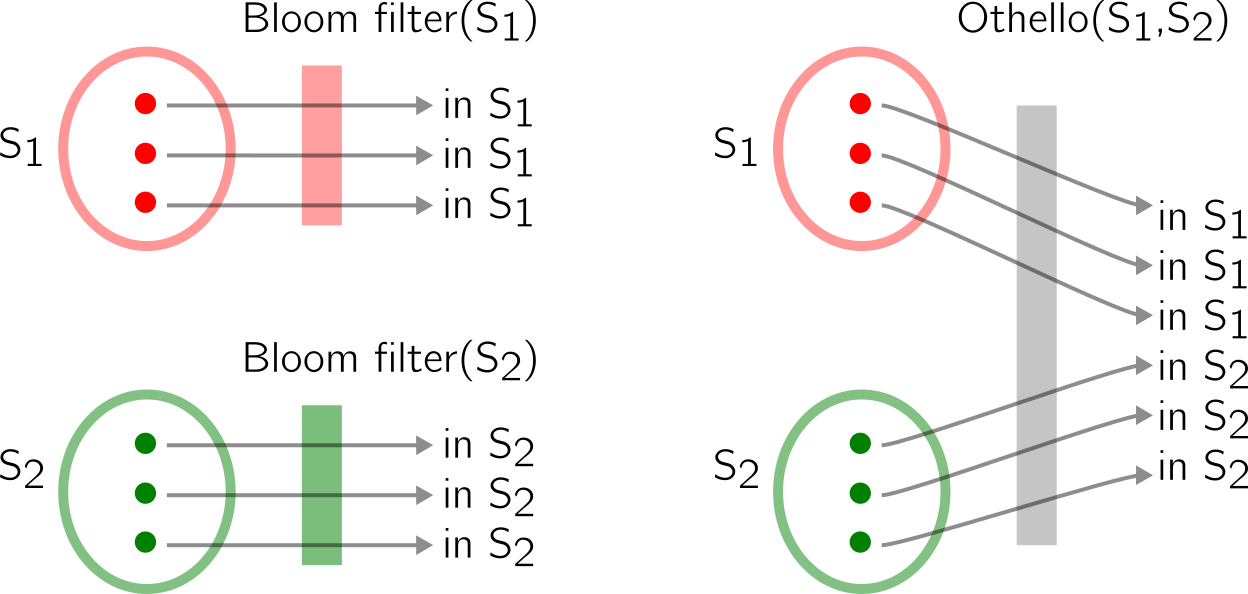
As I’ve said earlier, one Bloom filters informs you of the presence of an element in a set. A Othello tells you if an element is present in a set of disjoint sets. Let’s have a look at an example:
How does it work?
-
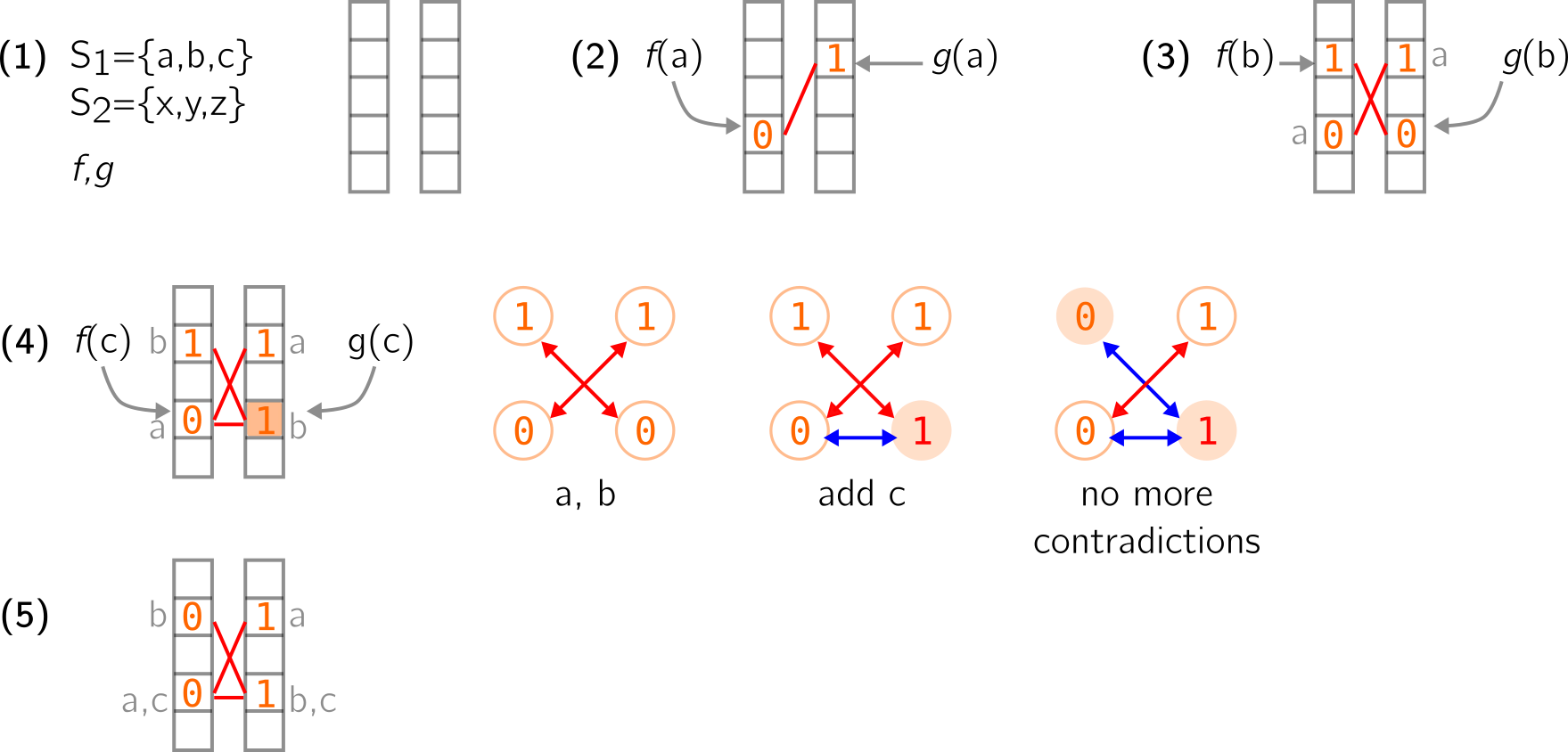
Let’s start with two vectors, a pair of (wisely chosen) hash functions and two disjoint sets S1 and S2 (see (1) below). We will store elements of S1 and S2 in the vectors using the hash functions. A rule is that an element from S1 must correspond to two different values in the two vectors, while an element from S2 must correspond to two similar values. So, elements from S1 must be associated with (0,1) or (1,0) pairs, and elements from S2 must be associated with (0,0) or (1,1) pairs. I choose to simplify the original article in which integers (not booleans) are used.
-
In (2) below, the first element a of S1 is added using the two hash functions f and g. It is associated with (0,1) using the two vectors. I use a red stroke to show that these two positions are linked. I’ll also write in grey, next to the vectors, the elements (though this information is not effectively retained).
-
In (3) same occurs for the second element b of S1.
-
In (4) above, the third element c of S1 is added too. However, it is hashed to two places that are already occupied. It leads to a contradiction because if values associated to c are (0,1), then the value in the right vector must be changed to 1 (colored position), which is problematic because b now has a (1,1) pair. To solve this issue, we can represent the occupied positions as a graph, with edges being the red links I draw before. The leftmost graph shows what happens when a and b are added. Two nodes that share an edge must have different values in this graph. When adding c, the blue edge is created and leads to change 0 to 1 (red node). However, there is now a (1,1) edge. So the change can be propagated along this edge, i.e., the other node’s value is switched as well (from 1 to 0). This leads us again to a graph that respects the given property, and to proper vectors in (5).
-
Fast forward in (6) below, we continued filling the structure with elements from S2. You can notice that any element from S2 is associated to a pair of similar values (I put green strokes to draw the links between values of a pair). For the query, we know that if a queried element is associated with a pair of different values in the structure, it comes from S1. If it is associated with a pair of similar values, it comes from S2. This can be converted to logical operations, XOR and XNOR. Elements are hashed, and these operations are performed on the result to check the membership (7 and 8 below). In practice, the structure can yield false positives (i.e., it tells you an element is in one of the indexed set, while in reality, it is not).
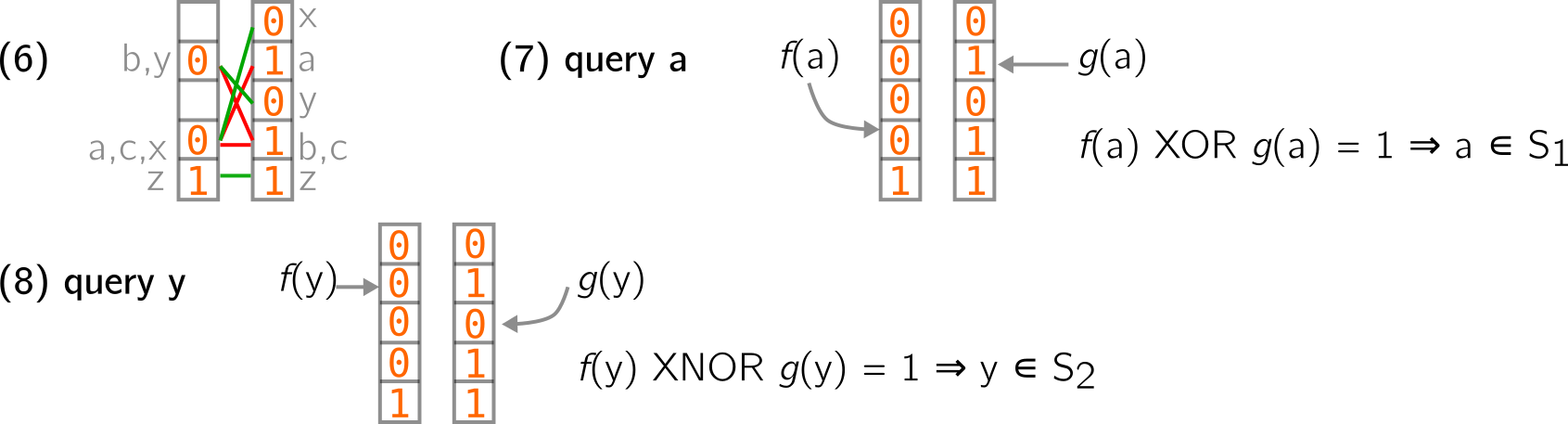
This concept can be further extended to more than two sets.
Othello in SeqOthello
Othello appears in bioinformatics in the method SeqOthello [10]. The context is still the same: associate k-mers with the datasets in which they appear. In order to obtain sets that are equivalent to S1, S2 in my previous example, we can compute equivalence classes on k-mers presence/absence in each dataset.
In the example below, two datasets contain three k-mers each, some are repeated, some are shared. We can summarize the presence/absence per distinct k-mer in a table. Then, we notice that only two patterns appear:
-
1- the k-mer appears in the green and orange dataset
-
2- the k-mer appears only in the orange dataset
Equivalence classes E1 and E2 record that information.

Then, a Othello can be used to map k-mers to E1 or E2 in a similar fashion than in previous examples. Thus, their original datasets can be guessed from the equivalence class they are mapped to (see below).
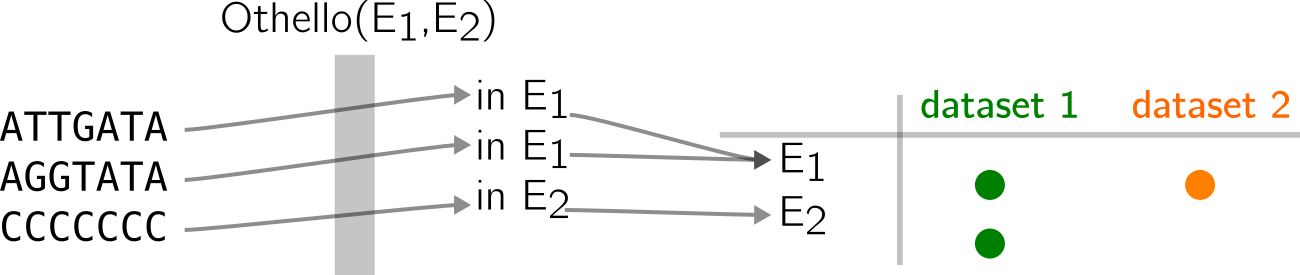
Again, there are lots of simplifications here. SeqOthello performs k-mer partitioning for better efficiency. Thus Othello is also used to compute k-mer buckets that will be compressed with adequate strategies, according to their presence/absence patterns. Othello will also work with way more classes in real life.
Next up: another hashing technique, minimal perfect hashing and in particular, the paper by Limasset et al. in 2017, and how to index k-mers with it.